
以太坊数据存取
- 文件大小:
- 界面语言:简体中文
- 文件类型:
- 授权方式:5G系统之家
- 软件类型:装机软件
- 发布时间:2025-01-18
- 运行环境:5G系统之家
- 下载次数:118
- 软件等级:
- 安全检测: 360安全卫士 360杀毒 电脑管家
系统简介
你有没有想过,那些在区块链上跳动的数字,其实就像是一群小精灵,在以太坊的世界里忙碌地穿梭?今天,就让我带你一探究竟,看看这些小精灵是如何在以太坊的舞台上翩翩起舞,完成它们的“数据存取”大戏的!
数据存取,一场魔法般的旅程
想象你手中拿着一张神奇的地图,上面标注着无数个宝藏地点。这些宝藏,就是以太坊上的数据。而数据存取,就像是探险家们按照地图找到宝藏的过程。那么,这些探险家们是如何在以太坊的世界里找到宝藏的呢?
RLP编码:数据的魔法咒语

在以太坊的世界里,所有的数据都经过了一种叫做RLP(Recursive Length Prefix)的编码。这就像是一种魔法咒语,能够将复杂的数据结构变成一个个简单的字节序列。RLP编码的规则非常巧妙,它能够根据数据的大小和类型,自动生成一个前缀,告诉接收者这个数据序列的长度和内容。
比如说,一个长度为10个字节的字符串,RLP编码后,会变成一个11字节的序列。前两个字节是0x81,表示这个序列的长度是10个字节,后面跟着的就是原始的字符串数据。
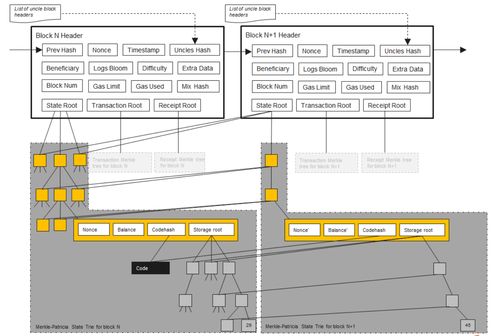
MPT结构:数据的迷宫
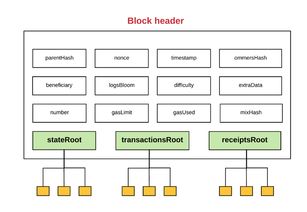
以太坊的数据存储结构,就像是一个迷宫,而MPT(Patricia Merkle Prefix Tree)就是这座迷宫的地图。MPT是一种特殊的树形结构,它能够高效地存储和检索大量数据。在MPT中,每个节点都代表一个数据块,而节点之间的连接,则代表了数据之间的关系。
当你需要查找某个数据时,你就像是在迷宫中寻找宝藏。通过MPT,你可以快速地定位到数据所在的节点,然后一步步地找到你想要的数据。
EVM:数据的舞台
EVM(以太坊虚拟机)是数据存取的舞台。在这个舞台上,智能合约的代码被翻译成机器码,然后由EVM执行。在EVM中,数据被存储在几个不同的位置:
- Stack:就像是一个临时存储空间,用于保存函数的局部变量。
- Args:用于存储函数的参数。
- Memory:用于存储函数的临时数据。
- Storage:用于存储智能合约的永久数据。
在EVM中,你可以使用各种指令来操作这些数据,比如将数据从Stack移动到Memory,或者将数据从Storage读取出来。
Geth-Query:数据的快速导出工具
在以太坊的世界里,数据量庞大,种类繁多。为了方便研究者们获取和分析这些数据,一些开发者们开发了各种工具,比如Geth-Query。Geth-Query通过并行处理区块数据,实现了快速而全面地提取以太坊链上数据。实验证明,使用Geth-Query,数据导出速度相比传统方法提升了10倍左右。
Etherscan:数据的侦探
Etherscan是一个强大的区块链探测器,它提供了丰富的API和分析工具,帮助开发者和分析人员更好地理解和利用以太坊的数据。通过Etherscan,你可以轻松地查询区块、交易、账户和智能合约数据,就像是一位侦探在调查案件一样。
:数据的奇幻之旅
以太坊的数据存取,就像是一场奇幻之旅。在这个旅程中,我们看到了RLP编码的魔法咒语,MPT结构的迷宫,EVM的舞台,Geth-Query的快速导出工具,以及Etherscan的侦探。这些元素共同构成了以太坊数据存取的奇幻世界,让我们对区块链技术有了更深入的了解。在这个世界里,数据就像是一群小精灵,在以太坊的舞台上翩翩起舞,为我们带来了无尽的惊喜和想象。
下载地址



常见问题
- 2025-01-18 usdt真钱包页面
- 2025-01-18 windows系统宏
- 2025-01-18 以太坊钱包总数
- 2025-01-18 区块链与数字经济
装机软件下载排行

其他人正在下载
系统教程排行
主题下载
-
魔笛MAGI 摩尔迦娜XP主题+Win7主题
-

轻音少女 秋山澪XP主题+Win7主题
-

海贼王 乌索普XP主题+Win7主题
-

学园默示录 毒岛冴子XP主题+Win7主题+Win8主题