
比特彗星

- 文件大小:16.51MB
- 界面语言:简体中文
- 文件类型:Android
- 授权方式:5G系统之家
- 软件类型:装机软件
- 发布时间:2025-02-07
- 运行环境:5G系统之家
- 下载次数:493
- 软件等级:
- 安全检测: 360安全卫士 360杀毒 电脑管家
系统简介
你有没有想过,在浩瀚的数据海洋中,如何找到那些隐藏的宝藏呢?没错,就是那些看似无关,实则紧密相连的信息。今天,就让我带你一起探索一下这个神秘的世界——聚类!
什么是聚类?
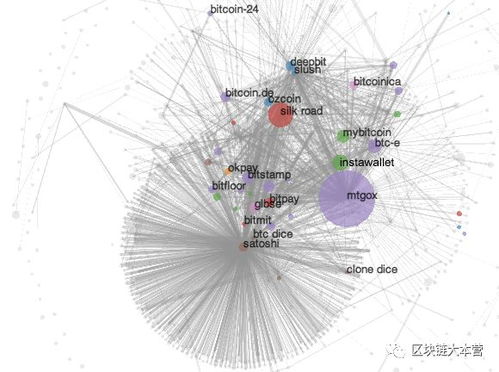
想象你手中有一堆五颜六色的糖果,你想要把它们按照颜色分类。这时候,聚类就派上用场了。它就像一位魔法师,能帮你把相似的东西聚在一起,让原本杂乱无章的数据变得井井有条。
简单来说,聚类就是将数据集划分为若干个簇,使得同一簇内的数据点彼此相似,而不同簇之间的数据点彼此差异显著。这个过程,就像给数据穿上了“魔法衣”,让它们瞬间变得有规律、有秩序。
聚类的魔法师:K-Means

在众多聚类算法中,K-Means可是当之无愧的“魔法师”。它就像一位经验丰富的老师,能迅速将数据分成K个簇,让每个簇都拥有一个“中心”,也就是我们常说的“质心”。
K-Means的工作原理很简单:首先,随机选择K个点作为初始质心;将每个数据点分配到最近的质心,形成簇;接着,重新计算每个簇的质心;重复这个过程,直到质心不再发生变化。
虽然K-Means算法简单易用,但它的“魔法”也有局限性。比如,它需要预先指定簇数K,而且对初始质心敏感,容易陷入局部最优。
聚类的其他魔法:层次聚类

除了K-Means,还有一位魔法师——层次聚类。它就像一位艺术家,将数据点之间的相似性绘制成一张“关系图”,然后根据这张图将数据点划分为不同的簇。
层次聚类分为两种:自底向上(凝聚聚类)和自顶向下(分裂聚类)。自底向上是将数据点逐渐合并成簇,而自顶向下则是将簇逐渐分裂成数据点。
层次聚类的优点是不需要预先指定簇数,而且可以生成聚类树(Dendrogram),直观地展示聚类关系。但它的缺点是计算复杂度高,对大规模数据不适用。
聚类的应用:无处不在
聚类的魔法不仅限于数据分类,它还能在各个领域大显身手。比如:
市场细分:通过聚类分析,企业可以了解消费者的购买行为和偏好,从而制定更有针对性的营销策略。
图像分割:聚类算法可以将图像划分为多个区域,方便后续的图像分析和处理。
文档分类:聚类可以帮助我们自动将文档归类,提高信息检索效率。
异常检测:聚类可以识别与众不同的数据点,应用于信用卡欺诈检测、网络入侵检测等领域。
聚类的未来:无限可能
随着人工智能技术的不断发展,聚类的魔法将会更加神奇。未来,聚类算法将更加智能化、自动化,为我们的生活带来更多惊喜。
聚类就像一位神奇的魔法师,能让我们在数据海洋中找到隐藏的宝藏。让我们一起期待,这位魔法师将为我们带来更多精彩的表现吧!



常见问题
- 2025-02-08 快穿之桃花修复系统
- 2025-02-08 我的女主播
- 2025-02-08 mindows工具箱
- 2025-02-08 以太之光无敌无限钻石版
装机软件下载排行

其他人正在下载
系统教程排行
主题下载
-
魔笛MAGI 摩尔迦娜XP主题+Win7主题
-

轻音少女 秋山澪XP主题+Win7主题
-

海贼王 乌索普XP主题+Win7主题
-

学园默示录 毒岛冴子XP主题+Win7主题+Win8主题